
At some point, most engineers have had to figure out how to keep two or more devices in sync, ideally in real time. In the server-to-device space, the popular options are database-like products such as Firebase, PouchDB and CouchDB, or AWS AppSync, where these vendors provide client SDKs that communicate directly with the database and manage synchronization. In the server-to-server space, what we typically see is the synchronization handled opaquely by the underlying distributed database you’re using, such as Cassandra or Riak.
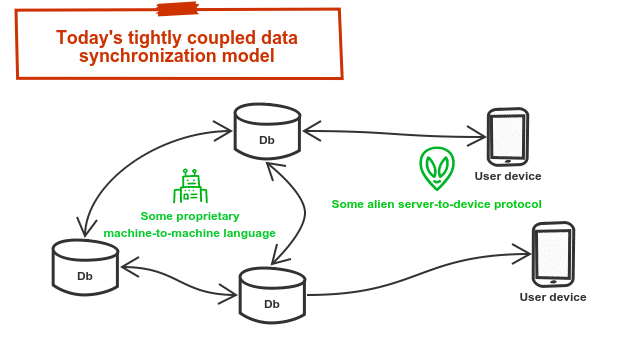
Whilst these solutions work well, one problem with them all is that they’re very tightly coupled, both in terms of the protocols they use to communicate, and also in the sense that all participants must communicate directly with each other, or at least via some proxy. When the participants in this data synchronization are heterogeneous systems, this tight coupling both at a protocol and communication perspective creates challenges.
Streaming Data is Eating REST APIs
In 2011 Marc Andreesseen made the bold statement that software was eating the world. It’s now 2018, and whilst sadly I can’t assert that streaming data is eating the world, streaming data is certainly eating REST APIs. Consumers now expect their apps to be up to date all the time (i.e. in real time). As a result, engineers are focussed on processing streams of data as they arrive instead of polling and batching updates. REST APIs are a great fit for request-response requirements, but offer little when it comes to solving realtime problems. So when realtime updates are needed, engineers are typically relying on streaming data solutions to allow them to receive and process data in realtime, and streaming products (like Kafka) and standards (like WebSub) are helping to fuel this movement.
However, whilst some progress is being made in regards to the transports used to deliver realtime data between different parties, little progress appears to have been made to help these decoupled parties synchronize their data over streaming transports.
This is a problem, because unlike the existing tightly coupled and largely “closed” systems mentioned at the start of this article, with streaming data delivery between different parties and devices you can’t assume:
- the publisher and subscriber can communicate directly. In fact, if you want a truly scalable and resilient solution, this coupling would probably be a bad idea;
- the publisher and subscriber share a common protocol for data synchronization.
Why is this a problem we should care about?
Platforms and products no longer operate as islands. In fact, in order for a product to be useful nowadays, it almost certainly needs to be integrated with other popular services. Zapier has grown quickly because they help solve this problem for platforms by providing a common architecture to receive and publish data using “hooks”.
But if you consider where we’re headed, and move beyond simple “hooks” that are really just events and triggers, it becomes clear that the need to keep organisations in-sync with each other in realtime is going to grow, and we don’t yet have the right tools to do this. Whilst moving data packets from one business to the other is solvable now using a streaming, queueing, batching or even polling transport, keeping the underlying data objects in sync is the problem. Consider the following contrived example for a crypto currency leaderboard.
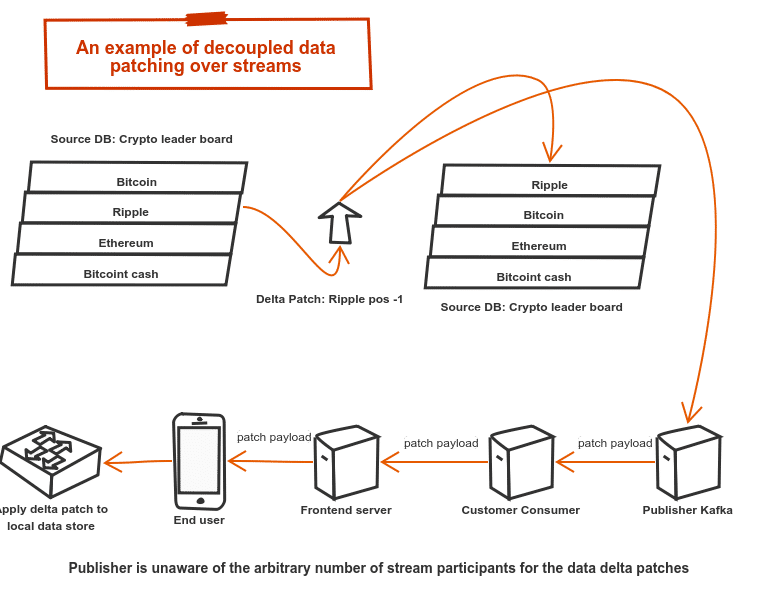
In this example, the end user’s mobile device receives data deltas for each change in the crypto leaderboard and not the entire object. For small objects this is hardly needed, but for very large objects or even entire databases, it is impractical to send the entire dataset each time and thus data deltas or some form of patch is needed to keep the publisher and subscriber in sync. However, when heterogeneous systems are involved and multiple streams are being used, it is no longer practical for all participants to share the same closed protocols, transports, or even assume the subscriber ever has access to the publisher.
A Proposal for Decoupled Data Synchronization
At Ably Realtime we’re seeing customers struggling with these data synchronization problems all the time, not just for server to device communication, but increasingly when using Ably to handle their entire realtime data workflow from and to third parties, and then potentially onto third party devices. In these scenarios:
- There is no guarantee that we are present at each stage in the data flow as other 3rd parties are involved. Relying on any proprietary Ably software becomes impractical as every participant in the stream processing would need to use our SDKs;
- The underlying delivery transports each participant will use vary immensely. Even within our own platform, we support MQTT, STOMP, AMQP, WebHooks, Lambda invocation, some competitor protocols and our own native socket based protocols. If you then consider all the protocols that third parties may use, any coupling for a data sync solution with delivery transports or protocols would be wholly impractical;
- The source database and target data stores are more often than not incompatible, and most importantly, the publisher does not know (and should not care) which data stores the eventual subscribers may be using.
For this reason, we’ve been thinking about a better way that would achieve the following:
- All streaming transports and even batching APIs are compatible because message payloads are opaque from the perspective of the transport. No new functionality or protocol knowledge is required by the transport.
- Neither publishers not stream subscribers need to implement any logic to generate or process data deltas or patches. They either use an open source vendor neutral SDK to generate these patches automatically, or they rely on the endpoint they are publishing to or subscribing to, to do this work for them by using that same SDK. The aim here is simplicity and to have no vendor lock-in. If the endpoint does not support generating patches automatically, then the publisher has the option to generate these patches beforehand.
- All stream participants who receive the streaming data, could in theory construct the underlying object that the patches apply to, or could instead be passive participants and simply pass on the messages. This allows any number of intermediaries to participate in stream processing without having any coupling to the payload contents or “meaning.”
Open Data Sync Protocol — very early working draft
Following the goals listed above, we’ve started working an open protocol that will enable decoupled participants to synchronize data objects over any streaming transport. You can see this work-in-progress draft at https://github.com/open-sdsp/spec.
With an open SDK in place to enable any publisher to easily generate data patches, and any subscriber to apply patches and construct the underlying object using that same open SDK, we believe decoupled data sync is truly possible:
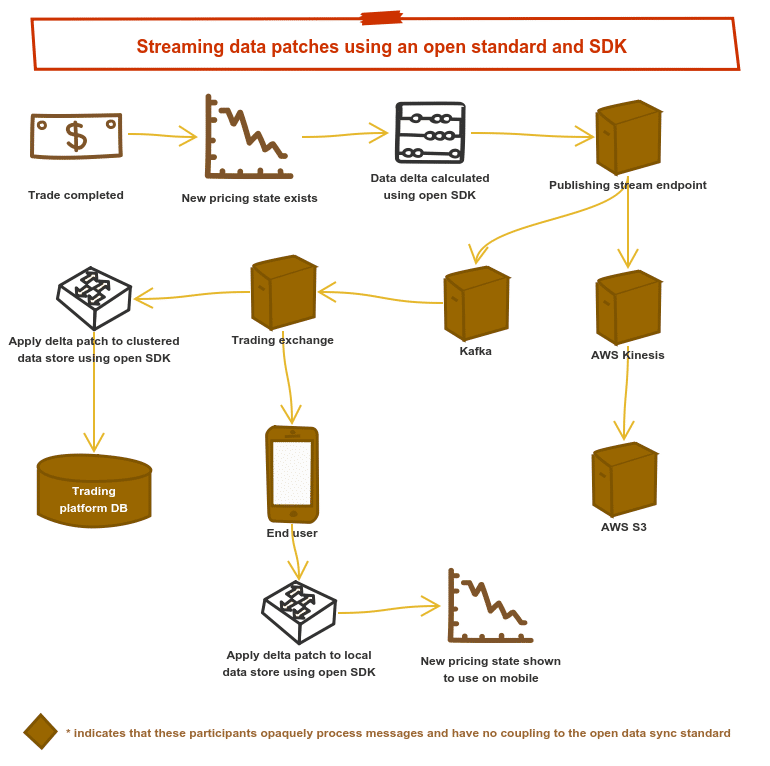
The hope for us now is to:
- Get participation from the industry and community to help shape this specification. If you’re reading this, please contribute.
- Build prototype open source SDKs in popular languages so that this protocol can be tested with real workloads. If you enjoy writing code and want to help with an SDK, please get in touch by raising an issue.
- Collectively we empower the developer community tackle data synchronization vendor lock-in by giving them the ability to independently choose and later change the database, streaming transport and data synchronization technology for their projects.
It’s early days for this specification, so please give us your feedback and participate if you think you may benefit from this proposed open standard.
See the working draft of the Open Streaming Data Sync Protocol here





