
At Ably, we provide a realtime messaging service that aims to deliver messages between globally-distributed participants with the lowest latency possible. When powering apps that enable realtime collaboration, or require time-critical updates, low and consistent latency is essential.
We recently deployed dedicated infrastructure for a new customer whose workload involved sporadic but highly time-critical updates between locations in Europe, South America and South East Asia. What we observed with this traffic was unusually high variance in the latency of messages passing through Ably between these locations. Taking the example of London (AWS region eu-west-2) to Singapore (AWS region ap-southeast-1), although the minimum transit time was close to the best possible at around 90ms, the slowest 5% of messages took over 400ms; this was much greater than our target for this particular workload of below 150ms. We set out to understand and fix whatever issues were causing that higher than expected variance.
Initial measurements
The round trip time between two machines can be measured using a utility called ping, which bounces packets between two machines. The ping time between our machines in London and Singapore was around 180ms, which meant that a packet could travel one way from Europe to SE Asia in 90ms. This implied that we could reliably deliver messages between Europe and SE Asia in 90ms, plus a small number of milliseconds for message processing at intermediate nodes.
When we measured our actual latency in the customer’s case, we found that 5% of messages took over 400ms to arrive instead of the expected 90ms. We refer to this figure as the p95 latency or the latency of the 95th percentile. An initial examination of our own code stack did not show a source of the delay, but we noticed that many of the messages were delayed by multiples of the 180ms round trip time (RTT), with peaks around 270ms and 450ms.
Initial investigation
This particular workload was sporadic, with periods of seconds when no messages were sent, followed by bursts of messages. We found that if we send a high rate of “heartbeats” (periodic messages), at the rate of 50 messages per second, the latency tails would disappear.
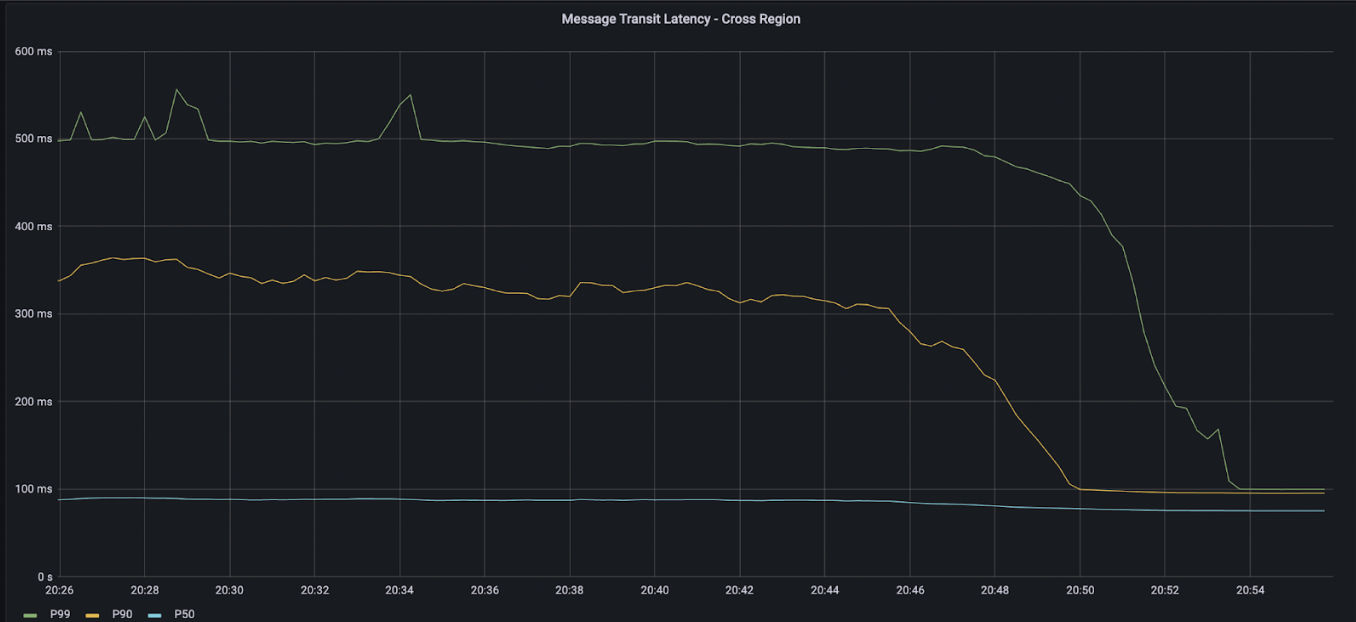
This led us to suspect that the source of the delay was message propagation delays on the actual TCP/IP connection, rather than processing delays arising from our own code. Normally, propagation delays might be due to congestion on a connection, but the fact that a higher message rate could eliminate the latency variance strongly suggested that the problem was not due to congestion.
In order to investigate further, we wrote a simple program which bounced TCP/IP messages between servers located in London and Singapore. Since we could reproduce the problem with our program, we were confident that the problem wasn't in our realtime messaging stack. This raised the question of whether our TCP stacks were mis-configured in some way to produce this behavior.
Investigating TCP/IP settings
A brief overview of TCP/IP
TCP is a reliable protocol which runs over an unreliable IP layer. The IP layer can drop or reorder packets, and the TCP layer provides guaranteed delivery; the TCP receiver acknowledges receipt of packets, and the TCP sender retransmits packets if this acknowledgement is not received within a timeout window, called Receive Time Out (RTO). This RTO is set to double the RTT of the connection.
If the TCP sender had to wait for an acknowledgement of each packet before sending the next one, it would transmit data at a very slow rate, especially on connections with a large round trip time. To avoid this, TCP has a congestion control window, which specifies how many unacknowledged packets can be in flight at any given time. The size of this window is dynamically adjusted by the sender side to maintain an optimal size. If the window size is too small, then the bandwidth of the connection will be too small. But if it is too large, intermediate routers on the connection path will suffer congestion, and either drop the packets (leading to the need to retransmit), or delay the packets by queuing them in large buffers.
TCP can be sent across a wide variety of physical links, covering every combination of bandwidth, latency, and reliability. For this reason, TCP connections start off with a small window size and send a small number of packets. This beginning phase of starting with a small window size and ramping up is called the slow start phase of a TCP connection. When these initial packets are successfully acknowledged, they increase the window size until packet loss occurs or latency increases. This behavior discovers the optimal transmit rate for a given link. The rate of incoming acknowledgements effectively clocks the transmission of packets to an appropriate rate. This rate can change during the lifetime of a connection, for instance due to changes of routing of a link, or due to changes in congestion of a segment of the link.
Investigating tcp_slow_start_after_idle
The Linux TCP stack has many knobs, which can be examined and controlled by files in /proc/sys/net/ipv4/. This directory contains 130 files. One which seemed relevant to the investigation was tcp_slow_start_after_idle, which is enabled by default.
The tcp_slow_start_after_idle setting in the TCP stack is defined as follows:
tcp_slow_start_after_idle - BOOLEAN
If set, provide RFC2861 behavior and time out the congestion
window after an idle period. An idle period is defined at
the current RTO. If unset, the congestion window will not
be timed out after an idle period. Default: 1So after an idle period defined as two round trip times, the TCP congestion window will reset to slow start mode, in which only two packets are allowed to be in flight.
The solution: disabling tcp_slow_start_after_idle
In our case, the RTT from Europe to SE-Asia was 180ms, so the Receive Timeout (RTO), defined as twice the RTT, would be 360ms. Our customer did have bursty traffic with entire seconds when no data was transmitted. These silent periods were not interminably long in the scale of human history, but they were long enough for tcp_slow_start_after_idle to kick in. When the customer did transmit the next message, if this message was larger than the initial congestion window size, then the TCP stack would send the first two packets (about 3kb) and then wait for an ack to be received. This explained the delay of 180ms seen on some messages.
Adding a high frequency heartbeat to our connection - which sent a message every 20ms - meant the receiver would return regular ACK packets, which un-blocked the congestion window and allowed queued packets to be sent. The constant flow of packets meant that the connection was never idle for long enough for tcp_slow_start_after_idle to kick in.
To validate this, we turned off tcp_slow_start_after_idle on our sending machine:
sysctl -w net.ipv4.tcp_slow_start_after_idle=0This led to an immediate decrease in our p99 times, from 358ms to 200ms, on our test TCPping program.
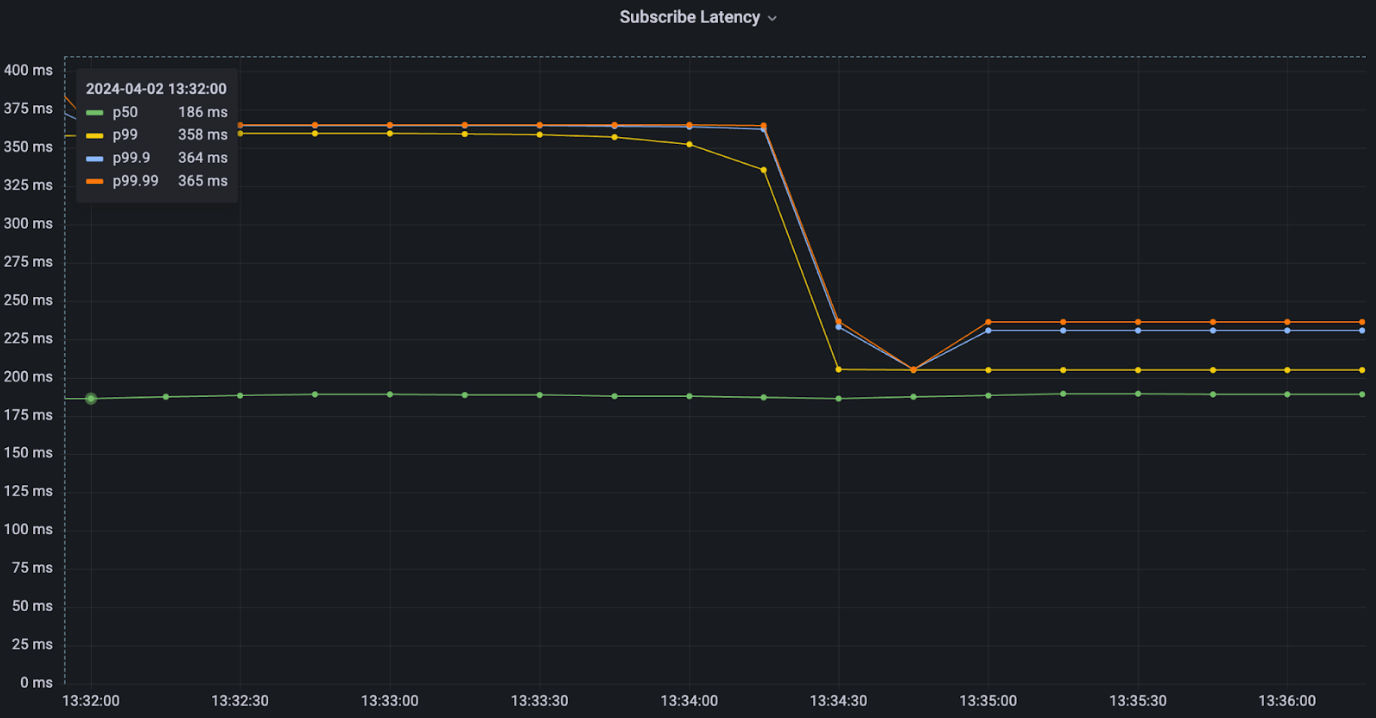
Disabling tcp_slow_start_after_idle in the container
However, our problems did not end there. To our surprise, disabling tcp_slow_start_after_idle on our machines did not remove the tail latencies in our production system, even though it worked for our TCPping benchmark. After some digging, we realized that the documentation for tcp_slow_start_after_idle setting in the Linux kernel was last updated in 2006 - two years before namespaces were added to the kernel. Docker containers are built on the functionality provided by these Linux namespaces, of which there are eight different types. One of these is the network namespace, which includes port assignments, routing tables, and its own private copy of network settings, such as tcp_slow_start_after_idle.
To disable tcp_slow_start_after_idle for a program running inside a container, you must disable it within the container itself, not on the host machine (the documentation does not mention this). If you are running your application inside a Docker container, you need to disable tcp_slow_start_after_idle within the container that runs your application. This can be done by writing 0 into the /proc/sys/net/ipv4/tcp_slow_start_after_idle file inside the container (if you have the appropriate permissions), or by using the --sysctl option when launching Docker. Once we launched our Docker containers with the appropriate option, the latency tails disappeared from our production system.
A note on observing window sizes in TCP/IP
We can observe the behavior in the previous sections directly by focusing on the congestion window.
tcpdump is the standard workhorse tool for observing network behavior, but it displays the receive window advertised by the receiver. This window indicates how much buffer space the receiver has for incoming data, which differs from the congestion window we are interested in. The amount of data the sender can transmit is limited by the smaller of the receive window and the congestion window.
Our focus is on the congestion window, which is managed by the sender's TCP stack and not transmitted over the network, making it invisible to tcpdump. However, we can examine it using a relatively obscure ss tool:
ss -i
which produces output like:
tcp ESTAB 0 0 [::ffff:127.0.0.1]:9302 [::ffff:127.0.0.1]:59210 cubic wscale:7,7 rto:204 rtt:0.023/0.015 ato:40 mss:32768 pmtu:65535 rcvmss:536 advmss:65483 cwnd:10 bytes_sent:72071646 bytes_acked:72071646 bytes_received:1320690 segs_out:21421 segs_in:27884 data_segs_out:20930 data_segs_in:6951 send 113975.7Mbps lastsnd:4764 lastrcv:4800 lastack:4764 pacing_rate 225500.2Mbps delivery_rate 65536.0Mbps delivered:20931 app_limited busy:584ms rcv_rtt:343162 rcv_space:65740 rcv_ssthresh:1178436 minrtt:0.005
The congestion window size is calculated with the formula cwnd * 2^wscale . In the output above, notice that wscale equals 7 , and cwnd equals 10. This comes out to 10 x 2^7 according to the formula, equal to 1280 bytes.
With tcp_slow_start_after_idle enabled, cwnd collapsed to 1280 bytes - one packet, when the connection went idle. After we disabled tcp_slow_start_after_idle, cwnd increased to a larger number when the connection was established, and stayed there.
Is the default setting for tcp_slow_start_after_idle wrong?

There was a certain degree of surprise from even some of our most experienced developers that the kernel's TCP stack delays packets after the connection becomes idle, and that the idle period timeout was so short.
tcp_slow_start_after_idle was introduced by Internet pioneer Van Jacobson in 1986 in response to severe congestion on the ARPAnet. During this period of dramatic growth, the network experienced a number of "congestion collapse" incidents, where large numbers of dropped packets led to TCP retransmits dominating internet traffic, effectively halting data transmission. In his 1988 paper Congestion Avoidance and Control Van Jacobson describes seven algorithms they added to the BSD TCP/IP stack (on which most other TCP stacks are based), to avoid these meltdowns. One of these was the slow-start phase of congestion control, which was used to clock the rate of packet transmission. When a connection became idle for more than two round trip times (RTTs), all ACK packets would have been received, and the congestion window would be emptied. If the sender resumed transmission, it could potentially send a full window of packets simultaneously, potentially overwhelming intermediate links in the connection. To prevent this, the TCP stack was given the default behavior to revert to slow start whenever the connection was idle for two RTTs, which ensures that a large number of packets are not simultaneously dumped into the connection in a way which could overwhelm intermediate routers.
This and other algorithms successfully prevented "congestion collapse," but they also introduced increased latency for bursty applications and unnecessary delays in situations where the network had sufficient capacity. Consequently, system administrators were given the option to disable tcp_slow_start_after_idle when appropriate.
In our case where a customer's message transmission was bursty, and the network capacity was sufficient to handle these message bursts at the sender's line rate, then the default behavior did cause unacceptable delays for a realtime application.
Conclusion
In 2024, the Internet has evolved into an essential part of daily life. We expect it to “just work”, and often take for granted that transmitted packets will appear at the other end without issue. However, when low latency is critical, as in our case with realtime messaging, it's sometimes necessary to delve into the intricacies of TCP/IP configurations.
Solving customer problems sometimes leads us to interesting journeys into the history of Internet infrastructure and the Linux networking stack on which much of it is based. In this particular case, our investigation revealed that the default TCP setting, tcp_slow_start_after_idle, while historically effective in preventing network congestion, was causing significant delays for our customer's bursty traffic. By disabling this setting within Docker containers, we successfully reduced latency variance and improved message delivery times.
This experience underscores the importance of understanding and optimizing network stack configurations tailored to specific use cases. Our journey highlighted that sometimes, the solution lies beyond our immediate software stack, requiring a deep dive into the foundational technologies that support our applications.
As software engineers, we naturally tend to look for solutions to problems in the software we control and are most familiar with. But sometimes we need to look further afield and be ready to explore and adjust the underlying settings that can impact our systems in less obvious ways.
TCP/IP has generally stood the test of time well. It works well on links with bandwidth ranging from 1200 bps packet radio links, to modern 400 GB network backbones, and with latencies spanning microseconds on LANs, to hundreds of milliseconds for satellite links. But designing for such a wide range of environments does inevitably mean compromises and trade-offs which are not always suitable for our particular use case, especially when latency is of prime importance.




