Apache Cassandra is trusted to scale at internet level and designed to scale without limits. Which is why, at Ably Realtime, we use Cassandra for our persistent storage of messages. Even so, we always knew it has limitations based on the capacity we maintain in the system.
After a series of incidents of over three evenings in early 2020, something happened to seriously disrupt our Cassandra installation. The stock solution of adding more nodes, and even increasing the size of the nodes, had little impact. Had Cassandra lost our trust?
These are the details of how we unearthed the culprit as Cassandra’s counter columns. A cautionary tale of using Counters at scale in production. How trusting the theory could cause havoc in practice, and how we restored our trust in Cassandra.
Background: How we use Cassandra at Ably
At Ably we use Cassandra for our persistent storage of messages and certain message metadata. It is a good fit for that use-case: the cluster is globally distributed and replicated, supports high write-throughput, and provides the application a good level of control over query consistency levels, on a per-query basis.
Using Cassandra in this way fits with the model of an AP system in terms of the CAP theorem. That is to say, during times when the system might be partitioned because of network problems, the system remains available, at the expense of consistency during the period in which it is partitioned.
We also use Cassandra to store various other entities, even where they don’t necessarily require the performance or capacity of that solution, because it helps minimise the number of moving parts that we need to operate.
Cells and upsert operations in Cassandra
Before we get onto counter columns, here’s a primer on how persistent storage operations work in Cassandra. Ultimately, understanding this helped us get to the bottom of what caused the outages.
In Cassandra, the unit of persistent storage is the cell, and cells are organised into wide rows, or partitions. Partitions belong to column families, which is the Cassandra name for a table. Any update operation causes cells to be upserted, and all cell updates are made with a last write wins (LWW) policy, using a query timestamp that is interpreted consistently at all storage locations.
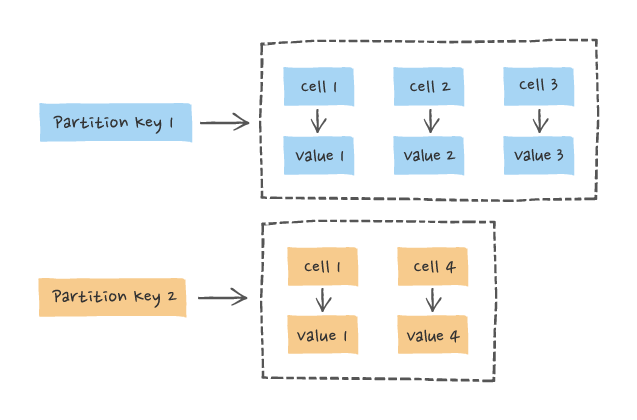
This means that all upsert operations commute, and any combination of updates can be applied in any order across all of the storage locations for a given cell with an eventually-consistent result.
In other words, an entire Cassandra database is a Conflict-free Replicated Data Type (CRDT), where the primitive operations are upserts and deletes to individual cells. Understanding the storage model in this way is the key to understanding its properties and behaviour with respect to network issues, write failures, storage failures, and so on.
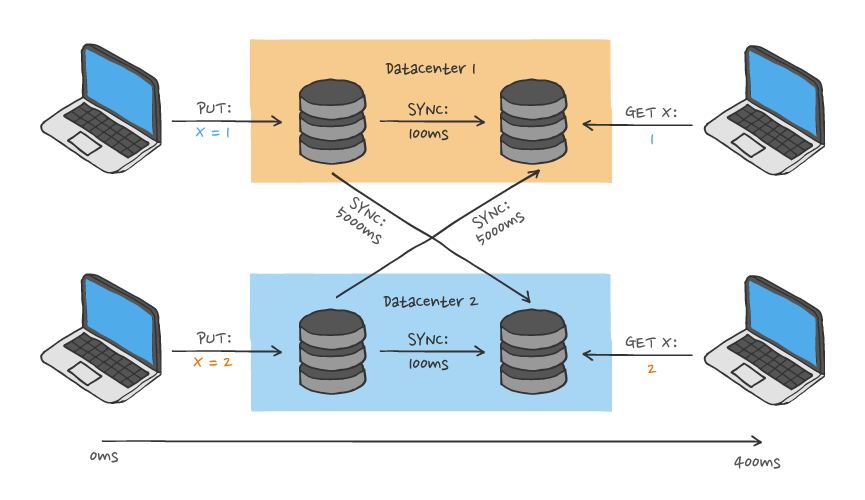
However, this model means that there are lots of use-cases that Cassandra cannot satisfy because it is inherently eventually consistent, and only on a cell-by-cell basis. (There is in fact one situation in which operations involving multiple cells can be relied upon to occur atomically when they belong to the same partition; but this does not change the essential nature of the consistency model.). Transactions that involve multiple partitions, or multiple column families are not possible, for example.
Cassandra has introduced some limited transaction support using Paxos and these operations, unsurprisingly, introduce a significant overhead and complexity, not to mention fragility, relative to the default storage and update semantics.
Introducing Cassandra counter columns
Cassandra also introduced counter columns as a way to support a certain kind of update atomicity in a much cheaper way than using Paxos. A counter column is a column that can contain integer values, and whose primitive operations are increment and decrement.
As is well known, you can implement a counter as a CRDT, where the increment/decrement operations are the primitive and commutative operations. In theory, if you have the same mechanisms for placement and distribution, and apply eventually-consistent updates, you should get a very usable distributed counter. It will have the AP resilience and performance that Cassandra provides for its regular storage model.
Use of counter columns at Ably
At least, that's what we thought when we adopted counter columns for part of the storage model at Ably. One limitation of Cassandra is it cannot efficiently count a partition. A query that counts the cells in a partition is O(N) in the number of cells within the query bounds. We needed an O(1) way to count certain partitions as part of a sharding strategy for certain records in our storage model relating to push device registrations.
Adopting counter columns comes with some issues.
- The most obvious constraint is that counter columns can only exist in tables that are made up entirely of counter columns. That means that you can't simply add a counter column to a table to represent the number of cells in any given partition - you need to create a new table, and have a partition in that table for each of the partitions in your first table. That's inconvenient, but not a showstopper. We didn't need the counter to be exact and, provided that the primary key space for both tables is the same, you would hope never to be in a situation where any given partition was not equally available for both tables.
- The next constraint is that a table, once declared as a counter table (that is, it is declared to contain at least one counter column) can never be deleted. Again, inconvenient, but not a showstopper.
- Finally, and a big disappointment of the counter model, is that counter update operations are not idempotent. That's losing one of the key attractions of updates in the primary storage model.
Still, we knew that we didn't need the counters to be exact - only approximate, and O(1) - so we accepted the limitations and proceeded. The functionality that relies on counter columns has been in production use for ~ 2 years.
How we tracked and resolved Cassandra counter column issues
Incident: Cassandra queries hog the space
We were alerted by production alarms that Cassandra queries were timing out for a large fraction of queries globally. Multiple Cassandra instances in each region were pinned to 100% CPU, and all production clusters were affected. This disruption affected our primary realtime messaging service. The time was 21:22.
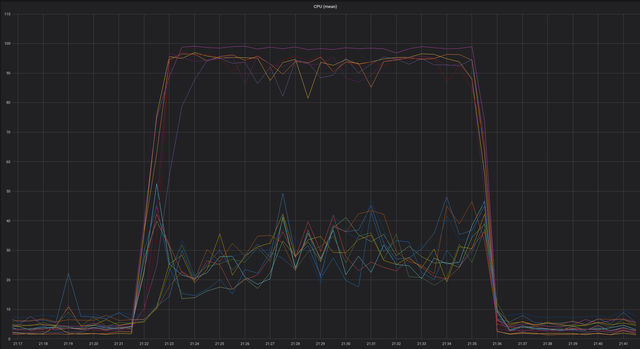
Although most message processing occurs without any interaction with the Cassandra layer, there are database lookups as part of certain operations (for example, the first use of an application in a given location, and persistence of some access tokens). Failure of these operations was impacting some customers significantly.
Our first actions in incident response were to try to establish the extent of the impact. Could we work around the problem by redirecting traffic? We also needed to understand the underlying cause. Since the impact was at the Cassandra layer, and affecting all regions and all clusters, redirection wouldn't help.
Another typical incident intervention, to scale up capacity, also wasn't available to us. Cassandra clusters can be scaled, but not in real time. None of our statistics on inbound requests indicated that any single request type was spiking, so there was no obvious way to suppress the source of the traffic. In fact, it wasn't even evident that the problem was caused by external load.
We determined that scaling Cassandra was the only way we could react, hoping to expand capacity to the extent necessary to handle the additional load. Just as we were about to do that, at 21:32, the load subsided as quickly as it had started, and service returned to normal. The cause of the load spike was still a mystery.
Step 2: Bigger Cassandra nodes, not more nodes?
Over the next day, we did everything we could think of to identify the cause. We ran updates, repairs, and trawled statistics, but there was no conclusive evidence of any problem. We scaled both horizontally and vertically, and assumed that we would then have sufficient capacity to handle a similar spike in the future.
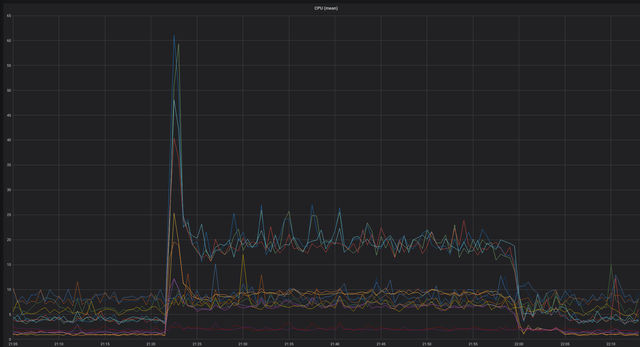
That day, exactly 24 hours after the first incident, the same thing happened. CPU load was at 100% in multiple instances in all regions. Again, we looked at the metrics, but couldn't see a demand spike. Again, after 10 minutes, the load subsided.
During the following 24 hours we added instrumentation to the API layer that sits on top of Cassandra, prepared to capture DTrace logs from affected instances, scaled vertically again, to the largest instance and volume capacities available. At 21:22 the load came again. With this additional capacity, it didn't max out the cluster, quite. We also had the data we needed to pinpoint the cause.
Step 3: Rate limiting stops the disruption
The giveaway was a huge number of requests for a single operation, on a single customer account. Each of those requests was resulting in multiple individual Cassandra queries, but included an update to a counter table.
The excessive number of queries appeared to come from a very aggressive retry strategy on the part of the application. Any query taking more than a few seconds to complete was retried. This resulted in many millions of requests once the load hit a certain threshold.
A bug elsewhere in our system meant that the rate-limiting that applies to every external API request was not applied to this specific request, allowing the very high request rate to reach the Cassandra layer. The application in question contained a large fleet of set-top box devices that were programmed to perform a re-registration with the system at the same time every day.
Resolution: Don’t use Cassandra counter columns
The underlying unanswered question, however, was this: why had the load - that is, before amplification through retries - started to reach the point where Cassandra query response times were degraded so significantly?
Each API request was resulting in multiple separate Cassandra upsert operations, and one counter column operation. We suspected the counter column as the likely cause of the problem, because we had not experienced comparable load from any other requests, even at much higher rates, that did not involve the counter column.
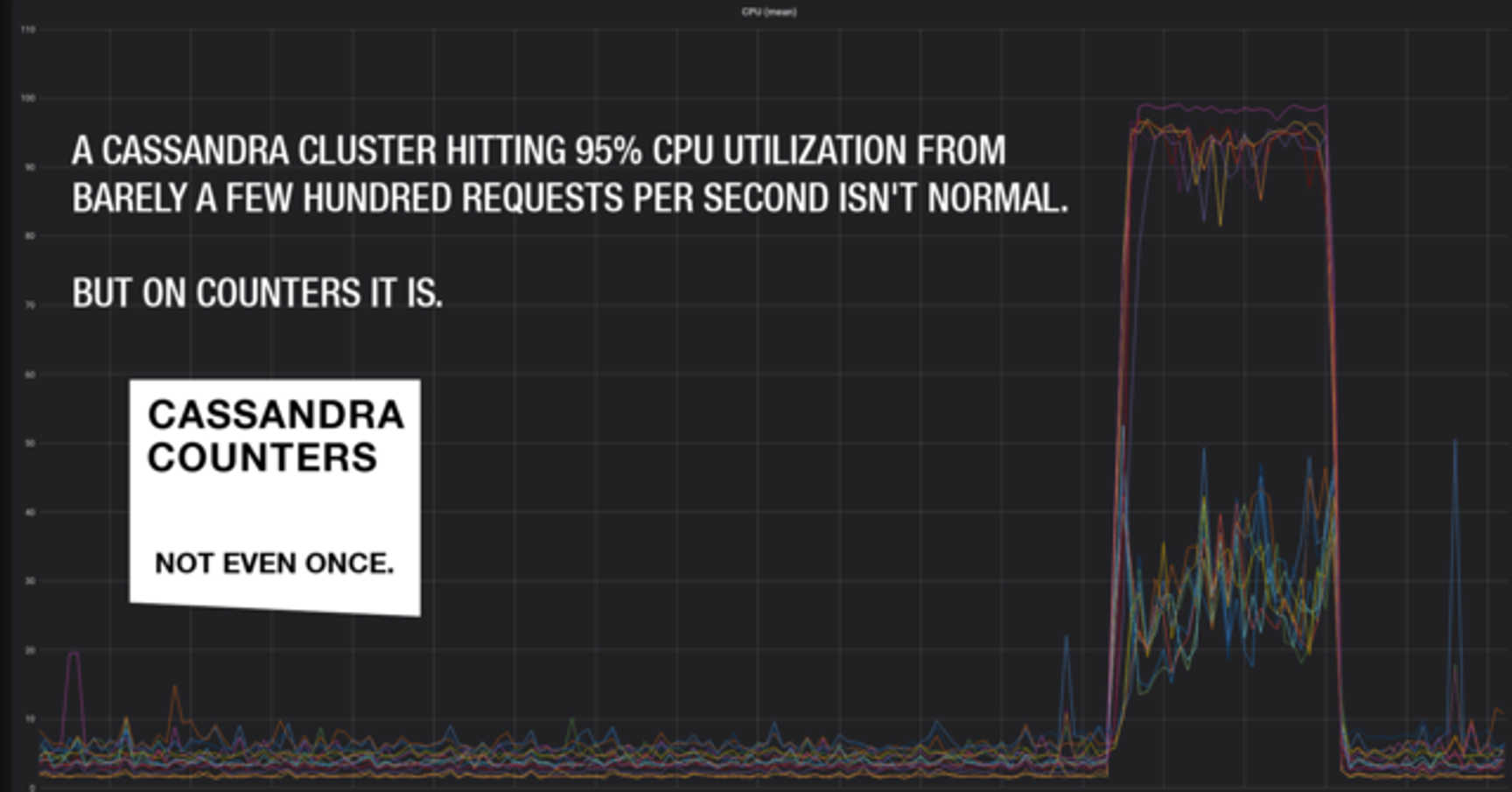
We redesigned the Cassandra layout for that data and changed the sharding strategy so that it did not use counter columns at all. We implemented the changes and deployed a few days later. The impact on system load was dramatic. Here is the graph over the days from the first incident to resolution:
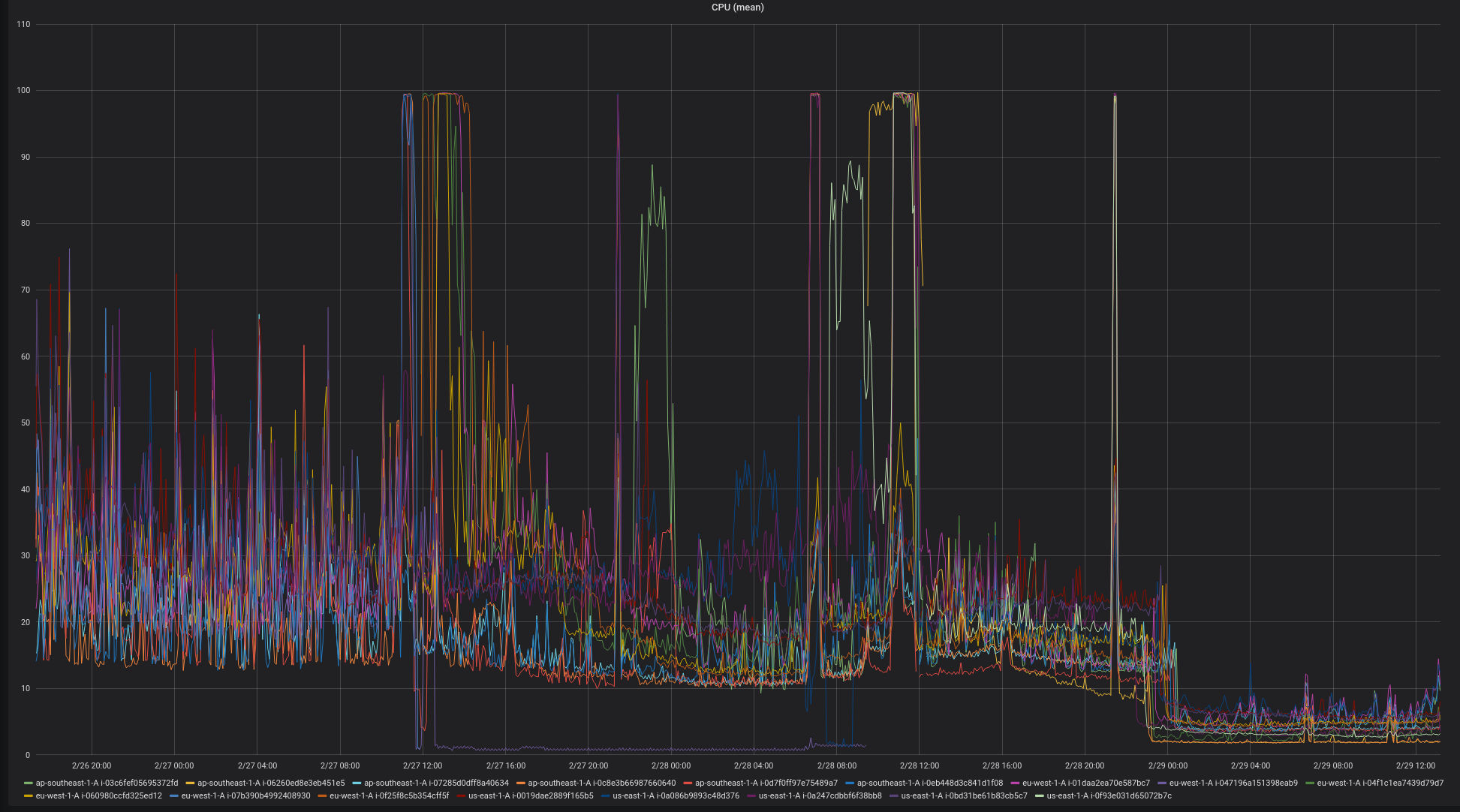
Eliminating the counter column operation reduced the load on the Cassandra instances by two orders of magnitude. This is a very surprising result, given that counters are advertised as being CRDT-like in their implementation and, in theory, should have comparable performance characteristics to the regular Cassandra storage model.
But, it gets worse. Further research shows that counter columns are not even eventually consistent (https://aphyr.com/posts/294-jepsen-cassandra#Counters). In fact, they don't appear to have any properties that make them a useful primitive for building predictable distributed systems.
Conclusion: Believe Cassandra, but don’t use counter columns
At Ably, we build systems that scale, and are predictable at scale. We learn about the theory of how to construct distributed systems, what trade-offs exist, and what properties of the constituent components are desirable in order to be able to reason about, and make claims for, their behaviour.
This cautionary tale seems to be about the perils of using column counters in Apache Cassandra. But really, the lesson we learned is that theory and practice are different things. With scale, along with the classical, theoretical concerns, come practical considerations. You have to take into account load, capacities, what happens when capacity is exceeded, and how peer systems react when services don't respond in the way we expect.
Also, nothing is built in isolation; everything we do builds on systems at lower layers that have their own theory versus practice trade-offs buried somewhere in their designs. There is bound to be some unexpected behaviour at some point.
Unlike the priestess Cassandra of greek myth, Ably Realtime is not in the business of making prophecies, whether they are believed or not. Just that expecting practice to always live up to theory can be hazardous. Oh, and don’t use Cassandra counter columns. Not even once.
Further reading
- Description of the CAP theorem in Wikipedia.
- For an explanation of counter columns, see this post on the Datastax website: What's new in Cassandra 2.1:Better implementation of counter columns
- Conflict-free Replicated Data Types are described in this article on Medium: CRDT.
- The Paxos family of protocols https://en.wikipedia.org/wiki/Paxos_(computer_science)




